

 Dünya üzerinde halihazırda 7.000’den fazla dil konuşuluyor. Ortalama bir insan ise en az iki dil biliyor, en azından böyle düşünülüyor. Büyük olasılıkla bunlardan biri anadili, diğeri ise okulda kendisine öğretilmiş olması gereken ikinci dil konumunda. Bununla birlikte dil, diğer insanları, kültürleri ve toplumları anlamanın önündeki en büyük engellerden birisidir. Hepimiz çok dilli olmayı istesek de, dünyanın sunduğu 7.000 dilin tamamını öğrenmemiz mümkün değil. Bu yüzden teknoloji arzuladığımız şeyi başarmamızda kritik öneme sahip.
Dünya üzerinde halihazırda 7.000’den fazla dil konuşuluyor. Ortalama bir insan ise en az iki dil biliyor, en azından böyle düşünülüyor. Büyük olasılıkla bunlardan biri anadili, diğeri ise okulda kendisine öğretilmiş olması gereken ikinci dil konumunda. Bununla birlikte dil, diğer insanları, kültürleri ve toplumları anlamanın önündeki en büyük engellerden birisidir. Hepimiz çok dilli olmayı istesek de, dünyanın sunduğu 7.000 dilin tamamını öğrenmemiz mümkün değil. Bu yüzden teknoloji arzuladığımız şeyi başarmamızda kritik öneme sahip. Meta’dan yapay zekalı SeamlessM4T
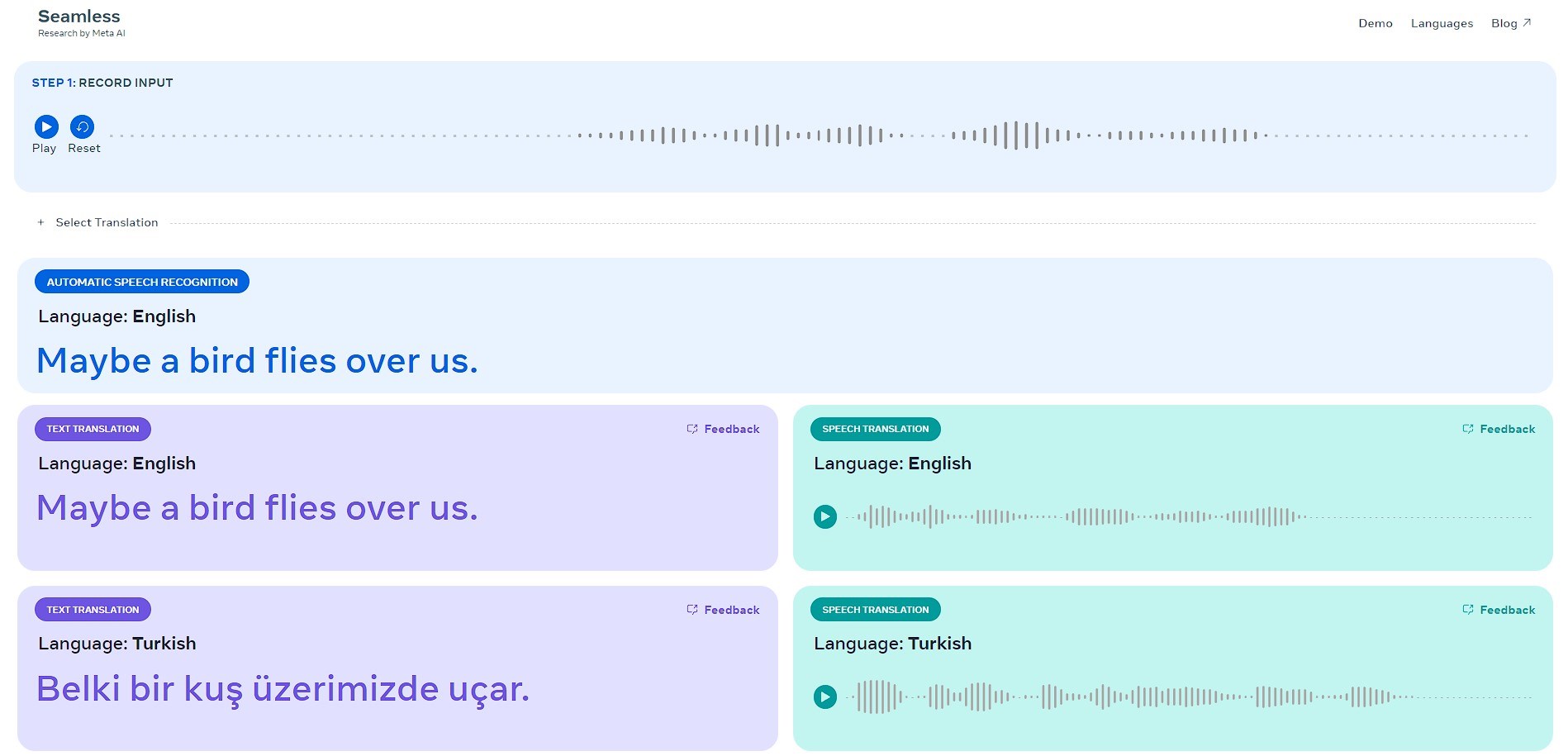
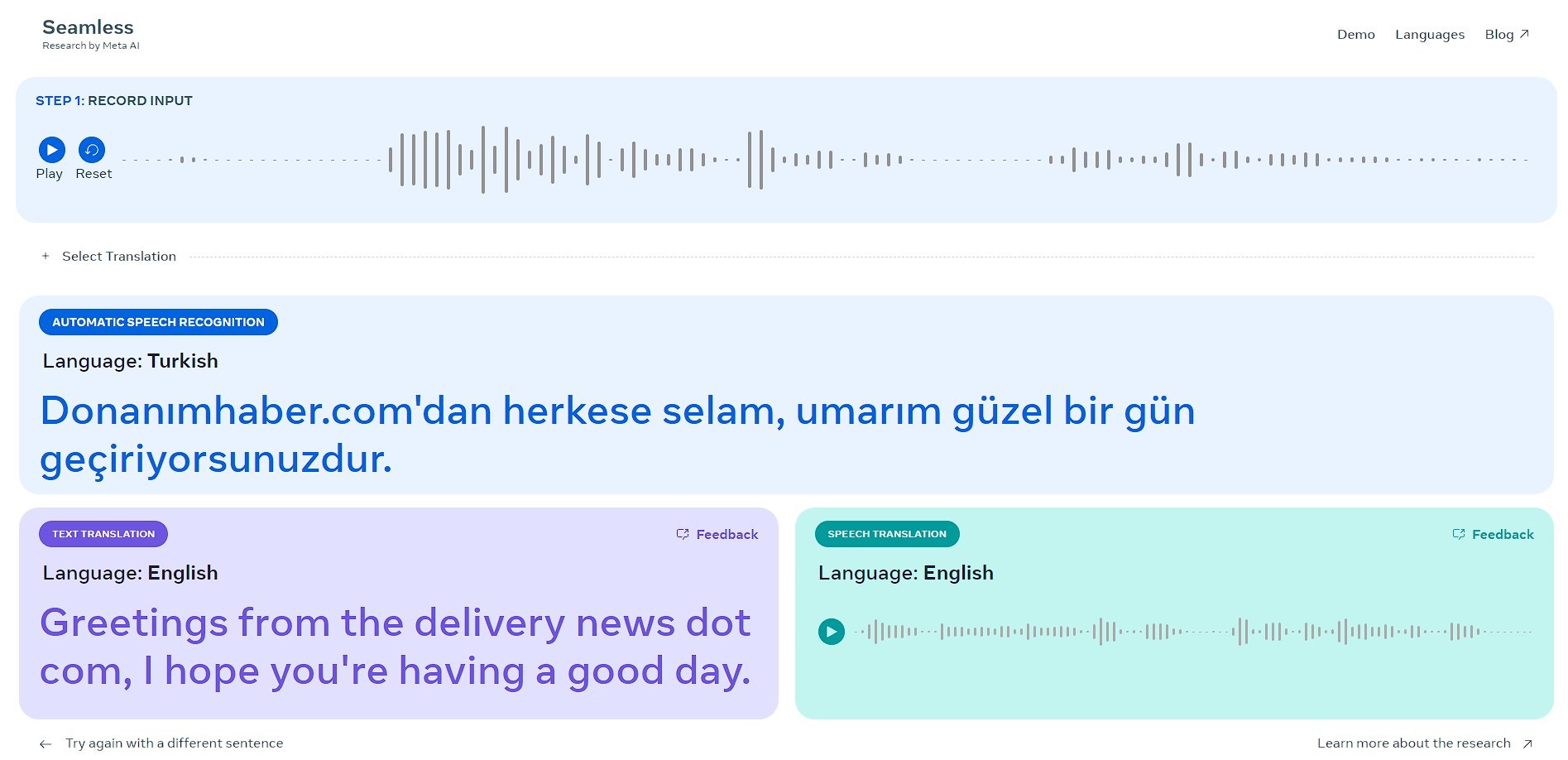 Bu bağlamda Meta, metin/konuşma çevirisi ve transkripsiyonu için çok dilli bir model tanıttı. SeamlessM4T olarak adlandırılan bu model genel olarak beş görevi yerine getirebiliyor: Konuşmadan metne, konuşmadan sese, metinden konuşmaya, metinden metne çeviriler ve konuşma tanıma. SeamlessM4T, halihazırda aralarında Türkçe’nin de bulunduğu 100 giriş dili ve 35 çıkış dili için konuşma tanıma ve çeviri yapabiliyor.
Bu bağlamda Meta, metin/konuşma çevirisi ve transkripsiyonu için çok dilli bir model tanıttı. SeamlessM4T olarak adlandırılan bu model genel olarak beş görevi yerine getirebiliyor: Konuşmadan metne, konuşmadan sese, metinden konuşmaya, metinden metne çeviriler ve konuşma tanıma. SeamlessM4T, halihazırda aralarında Türkçe’nin de bulunduğu 100 giriş dili ve 35 çıkış dili için konuşma tanıma ve çeviri yapabiliyor.
 Meta yapmış olduğu açıklamada “İçinde yaşadığımız dünya hiç bu kadar birbirine bağlı olmamıştı, bu da insanların daha önce hiç olmadığı kadar çok dilli içeriğe erişimini sağlıyor. Dolayısıyla herhangi bir dilde iletişim kurma ve bilgiyi anlama becerisi de giderek daha önemli hale geliyor” diyor.
Meta yapmış olduğu açıklamada “İçinde yaşadığımız dünya hiç bu kadar birbirine bağlı olmamıştı, bu da insanların daha önce hiç olmadığı kadar çok dilli içeriğe erişimini sağlıyor. Dolayısıyla herhangi bir dilde iletişim kurma ve bilgiyi anlama becerisi de giderek daha önemli hale geliyor” diyor. Açık kaynak
 SeamlessM4T, yeni bir dil öğrenmek isteyen veya dilini bilmediği yeni bir ülkede bulunan biri için faydalı olabilir. Açık kaynak yaklaşımına sadık kalan Meta, SeamlessM4T altındaki model koleksiyonunu, geliştiricilerin ve şirketlerin makine öğrenimi modellerini yüklemelerine olanak tanıyan bir platform olan HuggingFace’e yükledi. Model, SeamlessM4T-Medium ve SeamlessM4T-Large olmak üzere farklı boyutlarda iki versiyona sahip.
SeamlessM4T, yeni bir dil öğrenmek isteyen veya dilini bilmediği yeni bir ülkede bulunan biri için faydalı olabilir. Açık kaynak yaklaşımına sadık kalan Meta, SeamlessM4T altındaki model koleksiyonunu, geliştiricilerin ve şirketlerin makine öğrenimi modellerini yüklemelerine olanak tanıyan bir platform olan HuggingFace’e yükledi. Model, SeamlessM4T-Medium ve SeamlessM4T-Large olmak üzere farklı boyutlarda iki versiyona sahip. Meta ayrıca SeamlessM4T’nin üzerinde eğitildiği veri setini de yayınladı. SeamlessAlign olarak adlandırılan bu veri seti toplam 270.000 saatlik veriyi içeriyor ve Meta’ya göre bugüne kadarki en büyük açık çok modlu çeviri veri seti konumunda.
Meta ayrıca 4.000’den fazla konuşma dilini tanımlayabilen ve 1.100’den fazla dilde konuşma tanıma, dil tanımlama ve konuşma sentezleme teknolojisi sağlayan Massively Multilingual Speech modelini de piyasaya sürdü.
Evrensel dil çevirisi
Bu alanda bir öncü olan Google, bir metni çevirmek ya da konuşmayı bir dilden diğerine dönüştürmek için çoğu kişinin başvurduğu bir adres. Teknoloji devi şimdi de sınırlı sayıda insan tarafından konuşulan dilleri desteklemek için Evrensel Konuşma Modeli’ni (USM) geliştiriyor. Yapay zeka destekli model, 12 milyon saatlik konuşma ve 28 milyar metin cümlesi üzerinde eğitilmiş 2B parametre ile 1.000 dili destekleyecek. Bu aynı zamanda YouTube’un altyazı oluşturmak için kullanılan otomatik konuşma tanıma yazılımını da geliştirecek.
SeamlessM4T tüm küresel dillerin yalnızca bir kısmını kapsadığından model, evrensel bir dil çevirmenine doğru atılmış bir adım olarak düşünülebilir. Öte yandan ChatGPT, 95 dilde ve Bard ise 40 dilde konuşabiliyor.